
今天會帶大家使用
request
json
Beautiful Soup
嘗試擷取簡單的網頁資料
麻煩大家先透過pip install安裝這兩個套件
pip install beautifulsoup4 requests
這個四個學習目標一樣是
循序漸進
並且會持續延伸前面的概念去帶範例XDD
明天會嘗試帶大家到處爬線上的網站
在開始之前想複習一下
雖然我比較偏好從目標在反推回所學的工具
但如果沒有一點基礎背景會很難著手
所以我把昨天的目的列出來
並且大概貼出需要達成目的所需的知識點有哪些?
要使用那些python的套件
| 目的 | 知識點 | Python 套件 |
|---|---|---|
| 發送請求 | 理解 HTTP 協議、請求方法(GET、POST) | Requests、urllib |
| 解析 HTML | HTML 結構、DOM 模型 | Beautiful Soup、lxml、html5lib |
| 數據提取 | CSS 選擇器、XPath | Beautiful Soup、PyQuery |
| 處理動態內容 | JavaScript 基礎、AJAX 請求 | Selenium、Playwright |
| 數據儲存 | 數據格式(CSV、JSON、XML) | pandas、json |
| 異常處理 | 錯誤類型及處理機制 | 標準 Python 錯誤處理 |
| 網站規範遵循 | 了解 robots.txt 和網站使用條款 |
- |
| 性能優化 | 請求頻率控制、使用代理 | - |
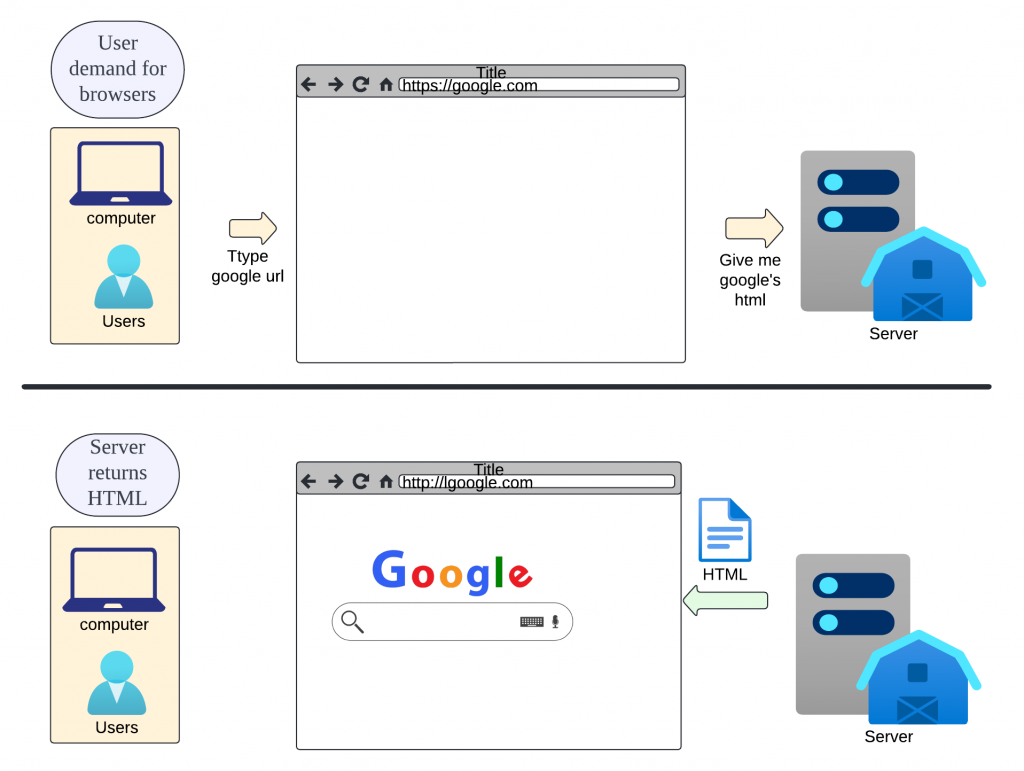
等等!? 類似的圖不適都已經爛掉了
為什麼還要丟出來解釋?
心路歷程 - 盲點
訪問?網頁
訪問這個詞其實很容易被大家誤解瀏覽器執行的動作模式
其實我想表達的是以前我認為瀏覽網頁
我們就是透過browser穿說在各個世界中
就像是我今天透過地標帶我去走到現場去觀賞房子一樣
但這件事情其實是錯的!!
因為事實上
我們也不是真的走到那個地方(server)去觀賞
而是透過請求去把資料透過某種形式丟回來 => 這也是我想表達的封面圖的意義
封面圖的意義 : 把瀏覽器想像成翻譯小秘書,可以把客戶的資料(server data)丟過來整理,再回傳給你(user)。那也有可能會因為翻譯小秘書不同,所得到的小資訊有所不同(browser的排版引擎會影響網頁排版)
我覺得這個知識點許多資深工程師都知道,但對新手來說是比較少被提到的誤解點
這個概念在以後做資料擷取或是前後端工程師會有重大影響!!
看到上面那張圖
其實我們可以總結幾個步驟
http 或 https)、域名、路徑及查詢參數。GET 請求頁面資源)/index.html)HTTP/1.1 或 HTTP/2)200 OK 表示成功)1. 使用者請求 URL -> 2. DNS 查詢 -> 3. 瀏覽器發送 HTTP 請求 ->
4. 伺服器接收並處理請求 -> 5. 伺服器返回 HTTP 回應 ->
6. 瀏覽器解析回應並渲染頁面 -> 7. 頁面顯示給使用者
其實這之中有許多的知識可以學習
但我們先理解到這邊就可以了
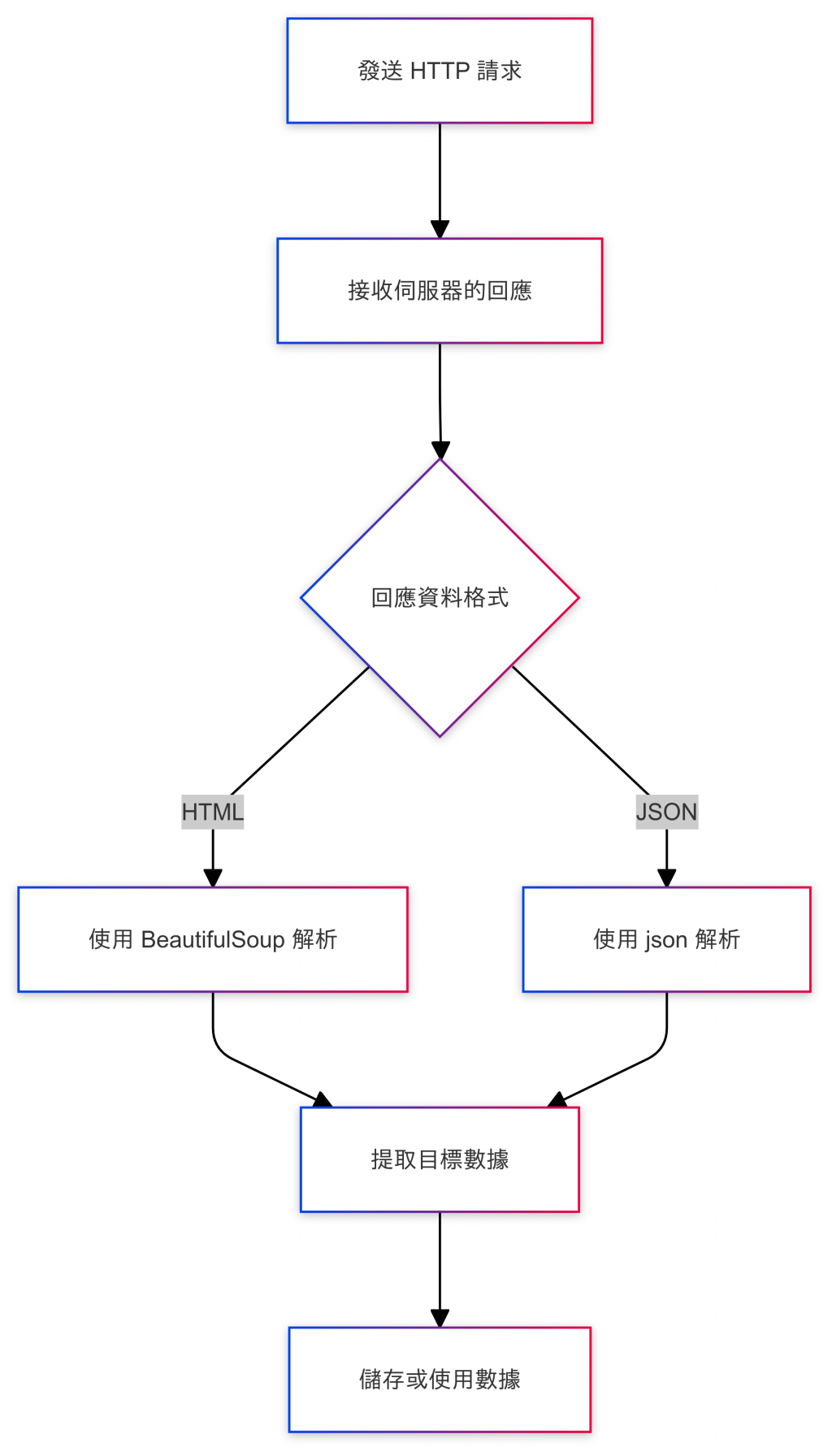
擷取 HTTP 資料通常稱為「抓取網頁數據」或「網頁爬蟲」。我們可以使用 Python 的 requests 模組來模擬 HTTP 請求,並從伺服器的回應中擷取數據。此外,配合BeautifulSoup 或 lxml 可以解析 HTML並提取特定的內容。
擷取 HTTP Data 的步驟
2.接收伺服器的回應
3.解析回應數據
4.提取目標數據
5.儲存或使用數據
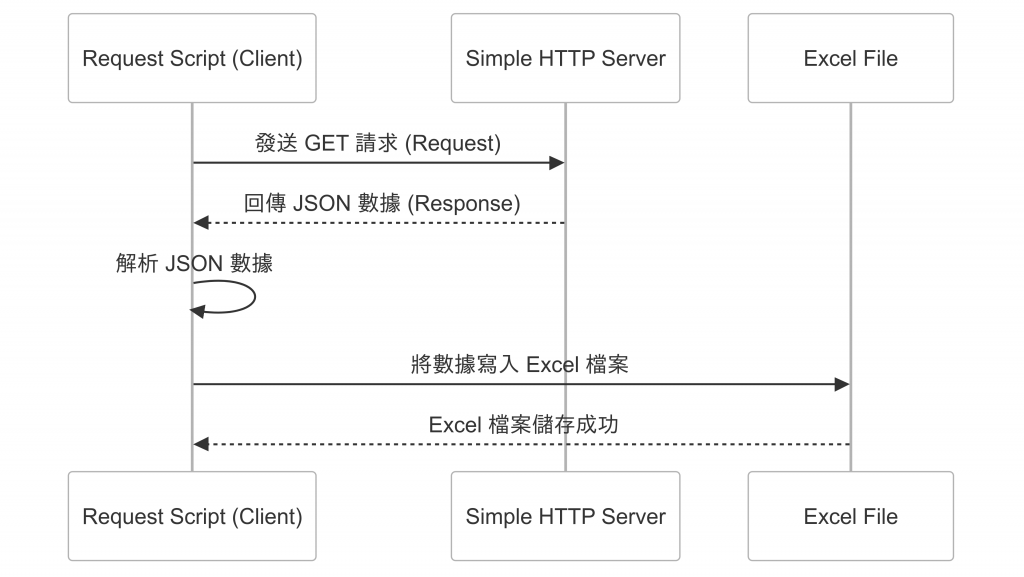
接下來我們就要實作兩隻程式
新手盲點
client 跟 server 可以在同台電腦上!? => 答案是可以的喔
其實client沒有限定說一定就要在你的裝置或手機,遠在你租的伺服器也可以是
那server 也沒有一定就要在cloud(AWS、Google Cloud...等)
這個點是新手很容易誤解的地方喔!!
主要是以需求作為目的請求資料方(client)以及提供資料方(server)這樣來看待
server.py
# server.py
import json
from http.server import BaseHTTPRequestHandler, HTTPServer
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# 設置回應標頭
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
# 傳送一些簡單的數據
data = {
"customers": [
{"id": "CUST1", "name": "王小明", "city": "台北市", "address": "中正區xx路"},
{"id": "CUST2", "name": "李大華", "city": "高雄市", "address": "三民區xx路"},
{"id": "CUST3", "name": "陳美麗", "city": "台中市", "address": "西屯區xx路"}
]
}
# 將數據轉換為 JSON 並傳送回應
self.wfile.write(json.dumps(data).encode("utf-8"))
# 啟動 HTTP 伺服器
if __name__ == "__main__":
server_address = ("", 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
print("伺服器正在運行...")
httpd.serve_forever()
你可以使用 python -m http.server 指令來啟動伺服器,這將提供靜態文件服務。
python -m http.server
or
python server.py
啟動時,如果是windows應該會詢問你是否同意啟動此程序 -> 這個步驟就是讓你打開8000 port當作server的意思,就不要猶豫同意吧(不要被駭客騙,按到不該按的就好了)
如果成功後,打開chrome輸入
http://localhost:8000/
如果成功就會看到以下畫面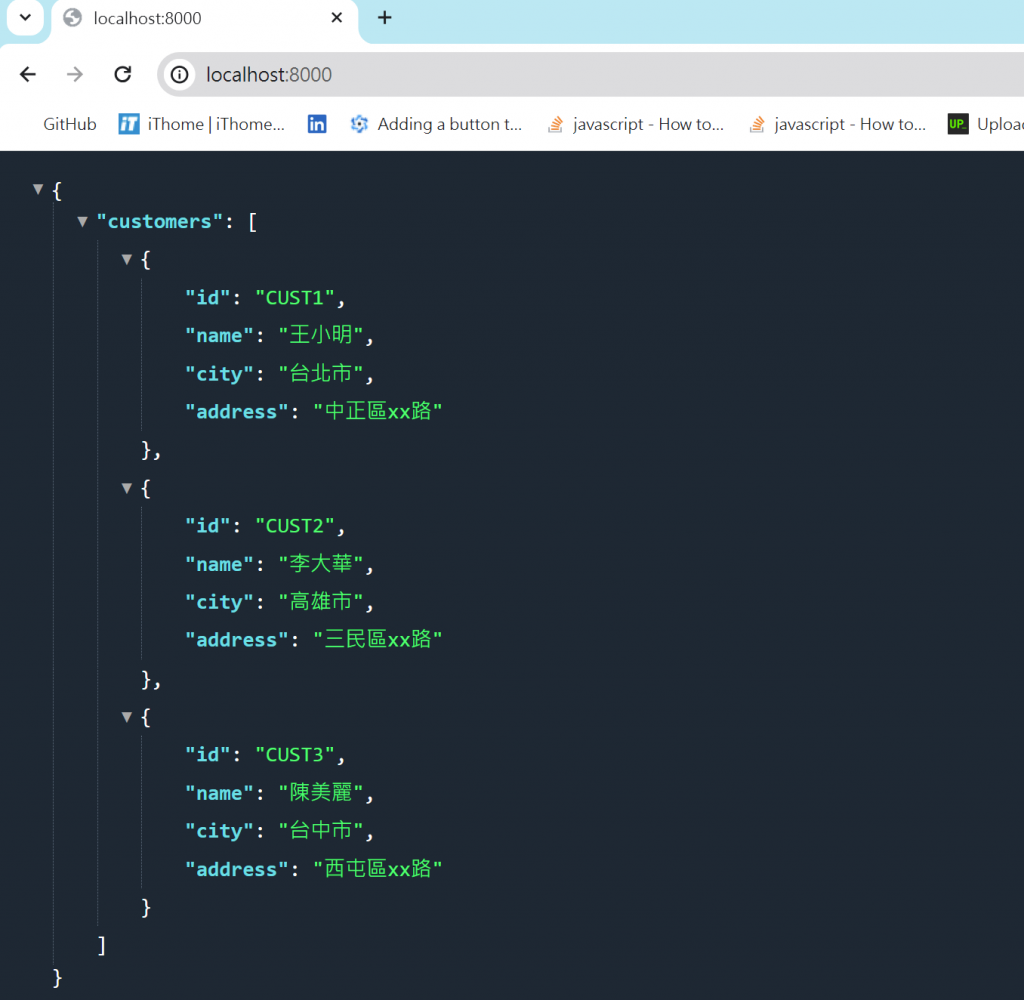
阿不對我的怎麼漲這麼醜?
其實我是有安裝這個插件-Json viewer pro
推薦可以裝這個插件
Json viewer pro
這個不論你是網頁工程師或是爬蟲測試資料人員都很好用喔
main.py
# main.py
import requests
import pandas as pd
# 向伺服器發送 GET 請求
response = requests.get("http://localhost:8000")
# 確認請求成功
if response.status_code == 200:
# 解析 JSON 數據
data = response.json()
# 轉換為 DataFrame
customers = pd.DataFrame(data['customers'])
# 將數據儲存到 Excel 檔案
customers.to_excel("customers_data.xlsx", index=False)
print("數據已儲存到 customers_data.xlsx")
else:
print(f"請求失敗,狀態碼: {response.status_code}")
執行main.py
python main.py
接者我們就可以透過把data做轉換成json()資料
再透過前面學到的panda把資料存到excel瞜
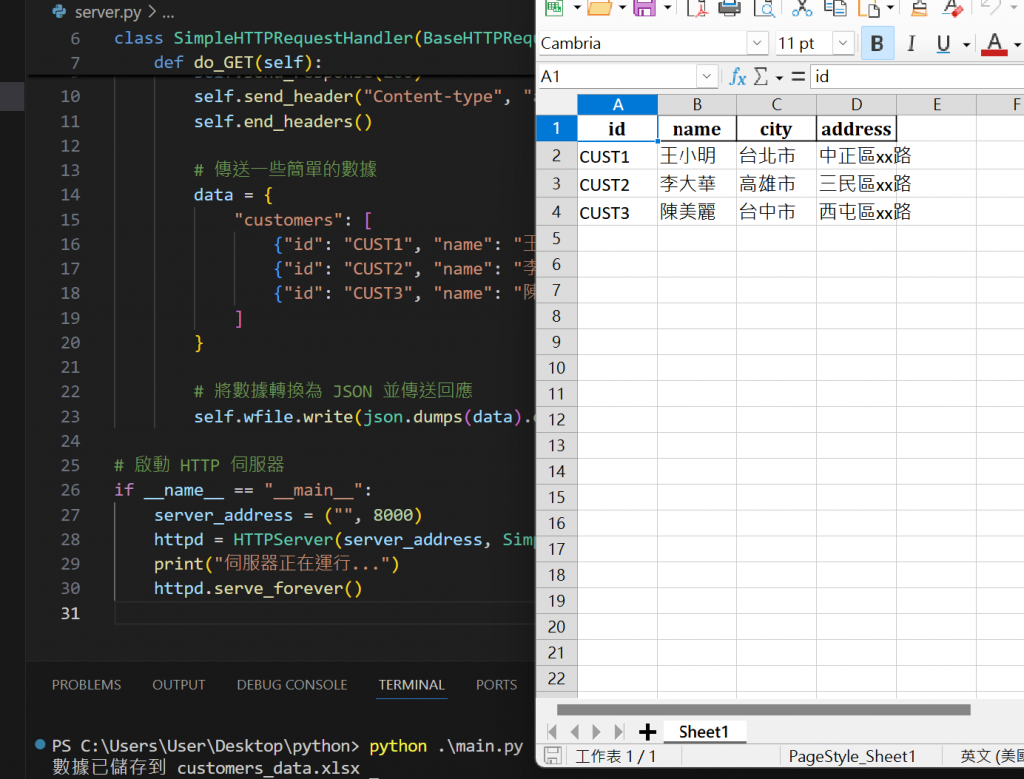
這樣我們就學到了簡單的call api 的動作瞜
其實透過瀏覽器去輸入網址也是HTTP的GET請求
所以我們可以透過瀏覽器把那份資料擷取出來
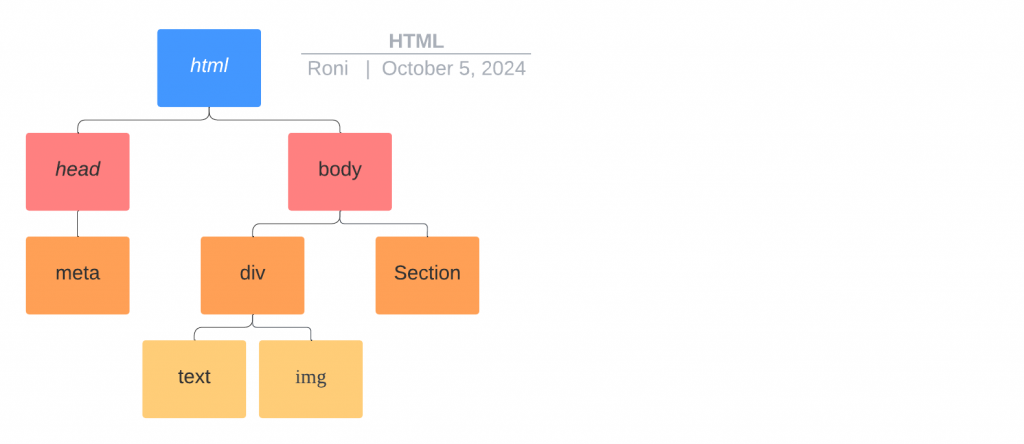
其實HTML格式並不會著墨太多點去說明
但簡單來說就是透過一個開始跟結束的tag去把內容像洋蔥一樣層層包起來
單層的架構
<h1>歡迎來到Roni網站</h1>
多層架構: HTML可以透過多層架構長出上面的樹狀圖,外層代表就是父節點
<section>
<h1>歡迎來到Roni網站</h1>
<div class="content">
<img src="..." alt="示例圖片">
<p>這是一段示例文本,描述了這張圖片的內容。</p>
</div>
</section>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>簡單的 HTML 範例</title>
</head>
<body>
<section>
<h1>歡迎來到Roni網站</h1>
<div class="content">
<img src="..." alt="示例圖片">
<p>這是一段示例文本,描述了這張圖片的內容。</p>
</div>
</section>
</body>
</html>
我們再透過http request 的get時
會拿到一坨這種語言
那爬蟲工程師的目的就是要去拆解架構再去擷取資料
以上面粒子來說,我想要roni網站的大標題
我就可以用爬蟲相關程式擷取(request)->再透過工具分析(h1 tag) 在儲存資料
| 元素 | 說明 | 應用場景 |
|---|---|---|
<!DOCTYPE html> |
定義 HTML 的類型,告訴瀏覽器該文檔使用 HTML5。 | 每個 HTML 文檔的開頭必須包含,以確保正確解析。 |
<html> |
根元素,包含所有顯示在頁面上的內容。 | 作為所有其他元素的容器。 |
<head> |
包含元數據,如網站標題、描述和鏈接到 CSS 文件等。 | 提供給瀏覽器和搜尋引擎的信息,但不會顯示在頁面上。 |
<title> |
設定網頁的標題,顯示在瀏覽器標籤上。 | 讓用戶識別網頁內容的重要性。 |
<body> |
包含所有可見內容,如文本、圖像和連結等。 | 用戶與之互動的主要區域,顯示所有網頁內容。 |
<header> |
頁面的頭部,通常包含網站標誌和導航鏈接。 | 提供網站的主要導航和品牌識別。 |
<nav> |
專門用於導航的區域,包含鏈接到其他頁面的連結。 | 提供用戶快速訪問網站不同部分的方式。 |
<main> |
主內容區域,包含主要信息。 | 用於放置網頁的核心內容,提升可讀性和結構化。 |
<footer> |
頁面的底部,通常包含聯絡信息和版權聲明。 | 提供額外信息,如版權、聯絡方式或社交媒體鏈接。 |
<section> |
用於將文檔分成不同主題部分的容器。 | 組織文檔內容,使其更具可讀性和結構化。 |
<article> |
表示獨立內容的部分,如文章或博客帖子。 | 用於顯示可獨立閱讀的內容,便於分享和引用。 |
建立index.html檔案
<!-- save this as index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Roni's Webpage</title>
</head>
<body>
<h1>Roni website</h1>
</body>
</html>
可以很簡單的建立index.html檔案
HTML可以直接透過瀏覽器開啟(大家可以透過chrome、firefox開看看)
# save this as http_server.py
import http.server
import socketserver
# 定義伺服器的端口
PORT = 8080
# 設定處理的 Handler 使用 HTTP Server
Handler = http.server.SimpleHTTPRequestHandler
# 啟動伺服器,並提供 index.html
with socketserver.TCPServer(("", PORT), Handler) as httpd:
print(f"Serving at port {PORT}")
httpd.serve_forever()
為什麼不需要指定 HTML 文件:
工作目錄:當你啟動 http.server 時,它會將你啟動伺服器的目錄作為根目錄(根目錄就是伺服器提供文件的地方)。
# save this as scraper.py
import requests
from bs4 import BeautifulSoup
# 發送 GET 請求到伺服器
url = 'http://localhost:8080/index.html'
response = requests.get(url)
# 確保請求成功
if response.status_code == 200:
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到 h1 標籤
h1_tag = soup.find('h1')
# 顯示 h1 的內容
if h1_tag:
print(f"Found H1 Title: {h1_tag.text}")
else:
print("H1 tag not found")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
soup.find('h1')
透過這個語法我們可以把html的h1標籤抓下來
這樣就大功告成了
今天循序漸學會了這些步驟
明天開始們就開爬網頁吧XDD
CSS的部分可以寫在html的屬性來決定
就像是幫HTML的架構上在套一層衣服一樣

| 階段 | 內容 | 重點 |
|---|---|---|
| 1. 基礎 HTTP 請求 | 理解 HTTP 協議 | - 請求方法(GET, POST, PUT, DELETE) - 狀態碼(200, 404, 500) - 優點:了解請求與響應的基本架構,方便調試和監控網絡請求。 |
| 使用 Requests 庫 | - 用法示例: python <br> import requests <br> response = requests.get('http://example.com') <br> print(response.text) <br> - 優點:簡化 HTTP 請求的流程,提升開發效率。 |
|
| 2. HTML 架構 | HTML 基礎 | - 常見標籤(<html>, <head>, <body>, <h1>) - 屬性(id, class, style) - 優點:理解 HTML 結構有助於更有效地設計網頁內容。 |
| CSS 基礎 | - 使用 CSS 來樣式化 HTML 頁面 - 優點:提升用戶體驗,增強網頁的可視性和可用性。 | |
| 3. HTML 爬蟲擷取 | 學習 BeautifulSoup | - 優點:自動化數據擷取,便於收集和分析網頁內容。 |

